이상 처리에 적합한 가상 데이터를 활용한 데이터 클리닝
문제 풀이 준비
데이터는 Pandas DataFrame 형식으로 제공하며, 각 열은 다음과 같은 속성을 가집니다:
- TransactionID: 거래 고유 ID
- CustomerID: 고객 고유 ID
- PurchaseAmount: 구매 금액 (USD)
- PurchaseDate: 구매 날짜
- ProductCategory: 제품 카테고리 (범주형 데이터)
- CustomerAge: 고객 나이
- CustomerGender: 고객 성별 (범주형 데이터)
- ReviewScore: 제품 리뷰 점수 (1~5 사이의 값, 결측값 포함
import pandas as pd
import numpy as np
# 가상 데이터 생성
data = {
'TransactionID': range(1, 21),
'CustomerID': [101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110],
'PurchaseAmount': [250, -50, 3000000, 450, 0, 300, 200, 150, -10, 800, 50, 75, 400, np.nan, 600, 1000, 20, 5000, 150, 80],
'PurchaseDate': pd.date_range(start='2024-01-01', periods=20, freq='ME').tolist(),
'ProductCategory': ['Electronics', 'Clothing', 'Electronics', 'Home', 'Electronics', 'Home', 'Clothing', 'Home', 'Clothing', 'Electronics', 'Electronics', 'Home', 'Clothing', 'Electronics', 'Home', 'Home', 'Clothing', 'Electronics', 'Home', 'Electronics'],
'CustomerAge': [25, 35, 45, np.nan, 22, 29, 33, 41, 27, 36, 28, 34, 42, 39, 24, 30, 32, 40, 38, 26],
'CustomerGender': ['Male', 'Female', 'Female', 'Male', 'Female', 'Male', 'Female', np.nan, 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female', 'Male', 'Female'],
'ReviewScore': [5, np.nan, 4, 3, 2, 5, 3, 4, 1, 2, np.nan, 4, 5, 3, 4, np.nan, 1, 5, 2, 4]
}
df = pd.DataFrame(data)
df.info() #정보 확인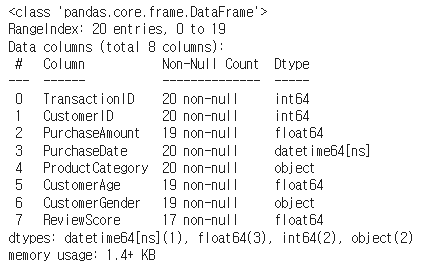
결측값 처리
PurchaseAmount, CustomerAge, CustomerGender, ReviewScore 열의 결측값을 적절히 처리하기
df.isnull().sum() #결측치 확인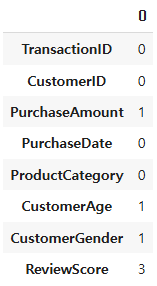
#PurchaseAmount는 평균값 , CustomerAge는 최소값, CustomerGender는 최빈값, ReviewScore는 중앙값으로 대체
df['PurchaseAmount'] = df['PurchaseAmount'].fillna(df['PurchaseAmount'].mean())
df['CustomerAge'] = df['CustomerAge'].fillna(df['CustomerAge'].min())
df['CustomerGender'] = df['CustomerGender'].fillna(df['CustomerGender'].mode()[0])
df['ReviewScore'] = df['ReviewScore'].fillna(df['ReviewScore'].median())
df
df.isnull().sum() #결측치 제거 확인
이상치 처리
PurchaseAmount 열에서 비정상적으로 큰 값과 음수 값을 처리하기
df.describe() #통계 정보 확인
#!pip install matplotlib #matplotlib 설치
import matplotlib.pyplot as plt
# 박스플롯으로 이상치 시각화
plt.boxplot(df['PurchaseAmount'])
plt.title('PurchaseAmount')
plt.show()
# PurchaseAmount의 음수 값 제거
df = df[df['PurchaseAmount'] >= 0]
# PurchaseAmount의 비정상적으로 큰 값 제거
df = df[df['PurchaseAmount'] < 1000]
#다시 박스플롯으로 데이터 확인
plt.boxplot(df['PurchaseAmount'])
plt.title('PurchaseAmount')
plt.show()
중복 데이터 제거
중복된 TransactionID가 있는 경우 제거하기
df = df.drop_duplicates(subset='TransactionID')
데이터 타입 변환
PurchaseDate 열의 데이터 타입을 날짜 형식으로 변환하기
df['PurchaseDate'] = pd.to_datetime(df['PurchaseDate'])
df.dtypes #데이터 타입 확인
정규화
PurchaseAmount 열을 정규화하기
from sklearn.preprocessing import MinMaxScaler
#값의 범위를 0과 1 사이로 변환
scaler = MinMaxScaler()
df['PurchaseAmount'] = scaler.fit_transform(df[['PurchaseAmount']])
범주형 데이터 선별 및 인코딩
ProductCategory와 CustomerGender 열을 인코딩하기
from sklearn.preprocessing import LabelEncoder
#라벨 인코딩
encoder = LabelEncoder()
#Electronics, Clothing, Home을 라벨링
df['ProductCategory'] = encoder.fit_transform(df['ProductCategory'])
#Male, Female을 라벨링
df['CustomerGender'] = encoder.fit_transform(df['CustomerGender'])
샘플링
데이터를 무작위로 5개 샘플링하기
sampled_df = df.sample(n=5, random_state=42)
데이터 전처리_결측치, 이상치
결측치(Missing Values)와 이상치(Outlier Values) 탐지 및 처리결측치: 데이터에 값이 없는 경우이상치: 데이터의 일반적인 패턴에서 벗어난 값, 문제의 정의에 따라 값을 새롭게 정의할 수 있습니다.
minjung405.tistory.com
데이터 전처리_중복 데이터 제거, 타입 변환, 인코딩
import pandas as pdimport numpy as np# 가상 데이터 생성data = { "Name": ["Alice", "Bob", "Alice", "David", "Eve", "Frank", "Gina", "Hank", "Ivy", "Jack"], "Age": [25, 30, "25", 35, 29, 40, None, 33, 30, 27], "Gender": ["F", "M", "F", "M", "F", "M",
minjung405.tistory.com